


首个AI高考全卷评测结果出分,大模型“考生”表现如何?
作者: 澎湃新闻 日期:2024-06-20 17:46 阅读:0 来源:澎湃新闻
据澎湃新闻报道,大部分大模型“考生”语文、英语科目表现良好,但在数学方面还有待加强。阅卷老师点评,在语文科目上,对于语言中的一些“潜台词”,大模型尚无法完全理解。在数学科目上,大模型的主观题回答相对凌乱,且过程具有迷惑性。
6月19日,首个大模型高考全卷评测结果公布。2024年全国高考结束后,大模型开源开放评测体系——司南评测体系(OpenCompass)选取了6个开源模型包括GPT-4o,针对高考全国新课标I卷“语数外”三门课程展开全卷能力测试。
评测结果显示,阿里巴巴开源的Qwen2系列MoE对话模型(Qwen2-72B)、GPT-4o及书生·浦语2.0文曲星(InternLM2-20B-WQX)成为本次大模型高考的前三甲,在语、数、英三门课程中得分均超过70分。大部分模型“考生”语文、英语科目表现良好,但在数学方面还有很大的提升空间。其中,书生·浦语2.0文曲星(InternLM2-20B-WQX)取得了数学单科的最高分,超越包括GPT-4o在内的所有模型。
司南评测体系OpenCompass是由上海人工智能实验室在去年7月的世界人工智能大会上推出,目前升级为OpenCompass2.0,构造了一套中英文双语评测基准,涵盖语言与理解、常识与逻辑推理、数学计算与应用、多编程语言代码能力、智能体、创作与对话等方面。
大模型语言能力表现良好,但数学有待提高
司南评测体系团队选取了GPT-4o及在2024年高考前开源的6个模型参与本次“大模型高考”评测。评测采用全国新课标I卷,参与评测的所有开源模型,开源时间均早于高考,确保评测 “闭卷”性。同时,成绩由具有高考评卷经验的教师人工评判,更加接近真实阅卷标准。
评测模型包括:法国AI创业公司Mistral于2024年4月17日开源的对话模型(Mixtral 8x22B)、零一万物公司于2024年5月12日开源的Yi-1.5系列最大的模型(Yi-1.5-34B)、智谱AI于2024年6月4日推出的最新一代预训练模型GLM-4系列的开源版本(GLM-4-9B)、上海人工智能实验室于2024年6月4日开源的书生·浦语2.0系列文曲星大语言模型(InternLM2-20B-WQX)、阿里巴巴于2024年6月6日开源的Qwen2系列MoE对话模型(Qwen2-57B)、阿里巴巴于2024年6月6日开源的72B稠密模型(Qwen2-72B)。
上述模型的高考“语数外”三科成绩结果如下表所示:
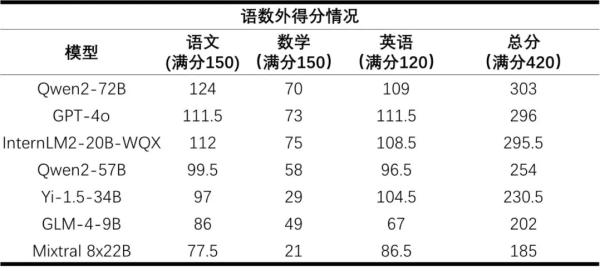
测评的大模型语数外得分情况 来源:上海市人工智能实验室
总分前三名阿里巴巴开源的Qwen2系列MoE对话模型(Qwen2-72B)、GPT-4o及书生·浦语2.0文曲星(InternLM2-20B-WQX)对应得分率分别为72.1%、70.5%和70.4%。大部分模型在“语言”本质上的表现良好,语文平均得分为67分,英语更是达到了81分。
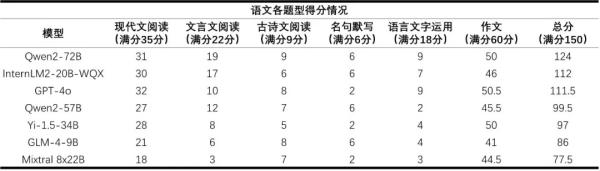
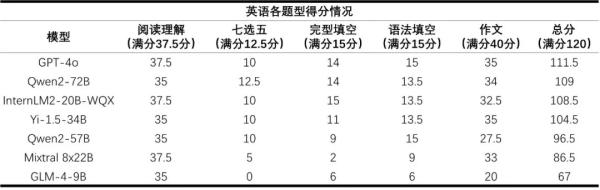
而数学则是所有大模型的短板,平均得分率仅为36%。得益于研究团队在数学推理上的投入,书生·浦语2.0文曲星(InternLM2-20B-WQX)取得了75分的最高分,超过所有受测模型。然而仍未达到及格水平,这表明大模型的数学能力存在较大提升空间。
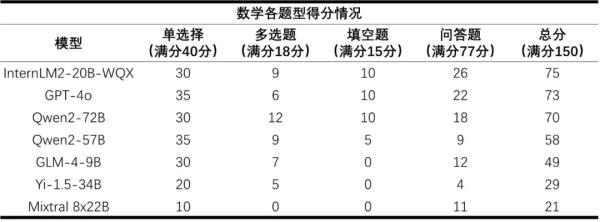
阅卷老师点评:大模型数学主观题回答凌乱
参与评测的所有开源模型,权重均在2024年6月7日高考题目公布前开源,避免了“数据污染”和“刷题”风险,与真实高考严格的“闭卷考试”一致,不存在“作弊”可能。
为贴近高考评卷模式,联合团队邀请多位具有阅卷经验的高中教师对模型主观题答案评分,每份考卷至少由3位教师分别打分。本次在完成所有大模型答卷的评卷工作后,研究人员同时邀请了各科教师对大模型表现进行了整体分析,为模型能力提升策略提供参考。
阅卷教师认为,在语文科目上,模型的现代文阅读理解能力普遍较强,但是不同模型的文言文阅读理解能力差距较大。大模型作文更像问答题,虽然有针对性但缺乏修饰,几乎不存在人类考生都会使用举例论证、引用论证、名人名言和人物素材等手法。多数模型无法理解“本体”“喻体”“暗喻”等语文概念。语言中的一些“潜台词”,大模型尚无法完全理解。
在数学科目上,阅卷教师表示,大模型的主观题回答相对凌乱,而且过程具有迷惑性,甚至出现了过程错误但得到正确答案的情况。此外,大模型的公式记忆能力较强,但无法在解题过程中灵活引用。
相较于语文和数学,阅卷教师认为,在英语科目上大模型整体表现良好,但部分模型由于不适应题型,在七选五、完形填空题等题型得分率较低。大模型英语作文普遍存在因超出字数限制而扣分的情况,而人类考生多因为字数不够扣分。
联合团队认为,如同高考阅卷也存在细微差异,由于主观题类型的引入,本次评测也无法做到绝对的公平。
司南评测体系OpenCompass于2023年7月由上海人工智能实验室在世界人工智能大会上推出,目前升级为OpenCompass2.0,构造了一套中英文双语评测基准,涵盖语言与理解、常识与逻辑推理、数学计算与应用、多编程语言代码能力、智能体、创作与对话等方面。
版权声明
1. 未经《新西兰天维网》书面许可,对于《新西兰天维网》拥有版权、编译和/或其他知识产权的任何内容,任何人不得复制、转载、摘编或在非《新西兰天维网》所属的服务器上做镜像或以其他任何方式进行使用,否则将追究法律责任。
2. 在《新西兰天维网》上转载的新闻,版权归新闻原信源所有,新闻内容并不代表本网立场。
版权声明
1.
未经《新西兰天维网》书面许可,对于《新西兰天维网》拥有版权、编译和/或其他知识产权的任何内容,任何人不得复制、转载、摘编或在非《新西兰天维网》所属的服务器上做镜像或以其他任何方式进行使用,否则将追究法律责任。
2. 在《新西兰天维网》上转载的新闻,版权归新闻原信源所有,新闻内容并不代表本网立场。
- 首发项目数量创新高,今年世界人工智能大会还有哪些亮点?
- 在岸、离岸人民币对美元汇率跌至去年11月中旬以来新低
- 前OpenAI首席科学家成立新公司:安全超级智能是唯一目标
- 梁静茹演唱会“柱子票”案判了:未构成欺诈,构成违约
- 挑战苹果PC,微软新动作
- 红海危机让参战美军陷入困境,寻求应对无人机袭击的新防御系统
- 芯片股逐步“攻占”市值榜,除了英伟达这两家成为近期热点
- OpenAI 前首席科学家 Ilya 宣布成立新公司
- 6月LPR报价出炉:1年期和5年期利率均维持不变
- 人工智能与人类未来会怎样?前沿科学家激辩30年后新图景
· 请您文明上网、理性发言
· 尊重网上道德,承担一切因您的行为而直接或间接引起的法律责任
· 您的留言只代表个人意见,不代表本站立场
· 天维网拥有管理笔名和留言的一切权利
· 您在天维网留言板发表的言论,天维网有权在网站内转载或引用
· 天维网新闻留言板管理人员有权保留或删除其管辖留言中的任意内容
· 参与本留言即表明您已经阅读并接受上述条款
查看所有评论 共( 条)
